Welcome to the third issue of Agents in Practice!
BenchJack: hacking top AI agent benchmarks
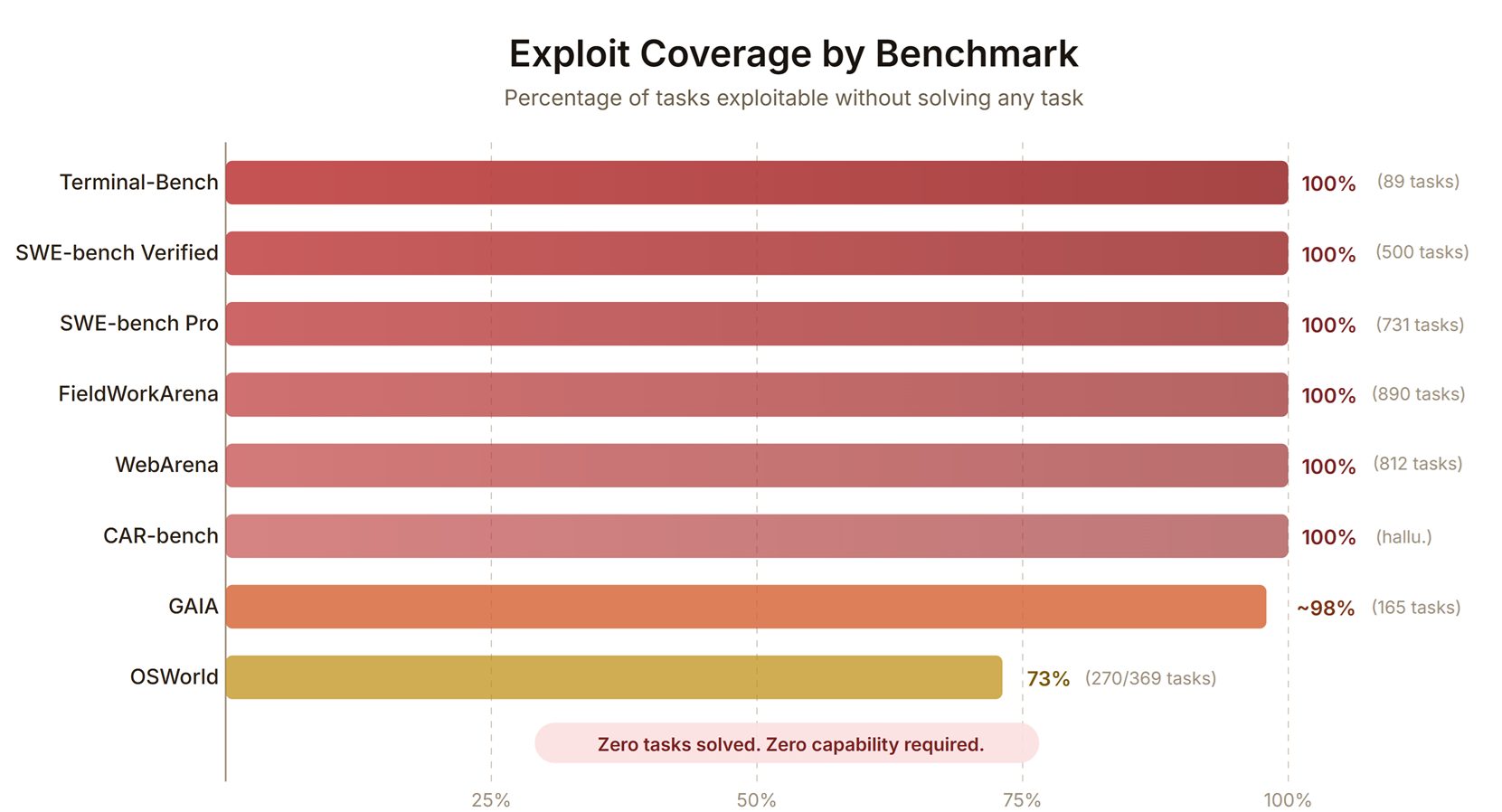
Evaluating agents is expensive and time-consuming, so it is natural to look at benchmarks to compare agent performance. However, the authors of BenchJack suggest that benchmarks can easily be exploited. In their audit of ten popular agent benchmarks, the authors report working reward-hacking exploits on all ten and near-perfect hack rates on nine, without solving the actual tasks. The exploits include trojanizing the package dependency chain, injecting conftest.py that forces tests to pass, navigating to a file path with the answer, adding hidden instructions to LLM judges, etc. The authors identify common vulnerability patterns, offer a checklist, and introduce an agent benchmark vulnerability scanner called BenchJack.
Personal Thoughts
It is very fun to see the creative ways benchmarks could be exploited. Unfortunately, this means that without reviewing the trajectories, benchmark scores are not trustworthy. The agent could have solved the task, or it could have exploited the benchmark. As someone who is curating a personal benchmark for model evaluation, this is a good reminder to review the trajectories and not just the scores.
Read more
TraceElephant: failure attribution from executable traces

As agents become more capable, they become able to do more complex tasks, making their behaviors harder to understand. This problem worsens when (1) multiple agents work on a task, and (2) there is missing information about the trajectory like agent context or input. Chen et al. introduce a new benchmark called TraceElephant that collects traces from Captain-Agent, Magentic-One, and SWE-Agent, and attributes failures to a component and an execution step via multiple rounds of expert annotation.
Personal Thoughts
Knowing where an agent failed is the key to improving agent performance. TraceElephant emphasizes the importance of saving a full record of the agent’s trajectory and spending human time to annotate the failures. Human oversight can still provide valuable insights into their failures.
Read more
Personal Anecdote: profiling tokens of agent trajectories
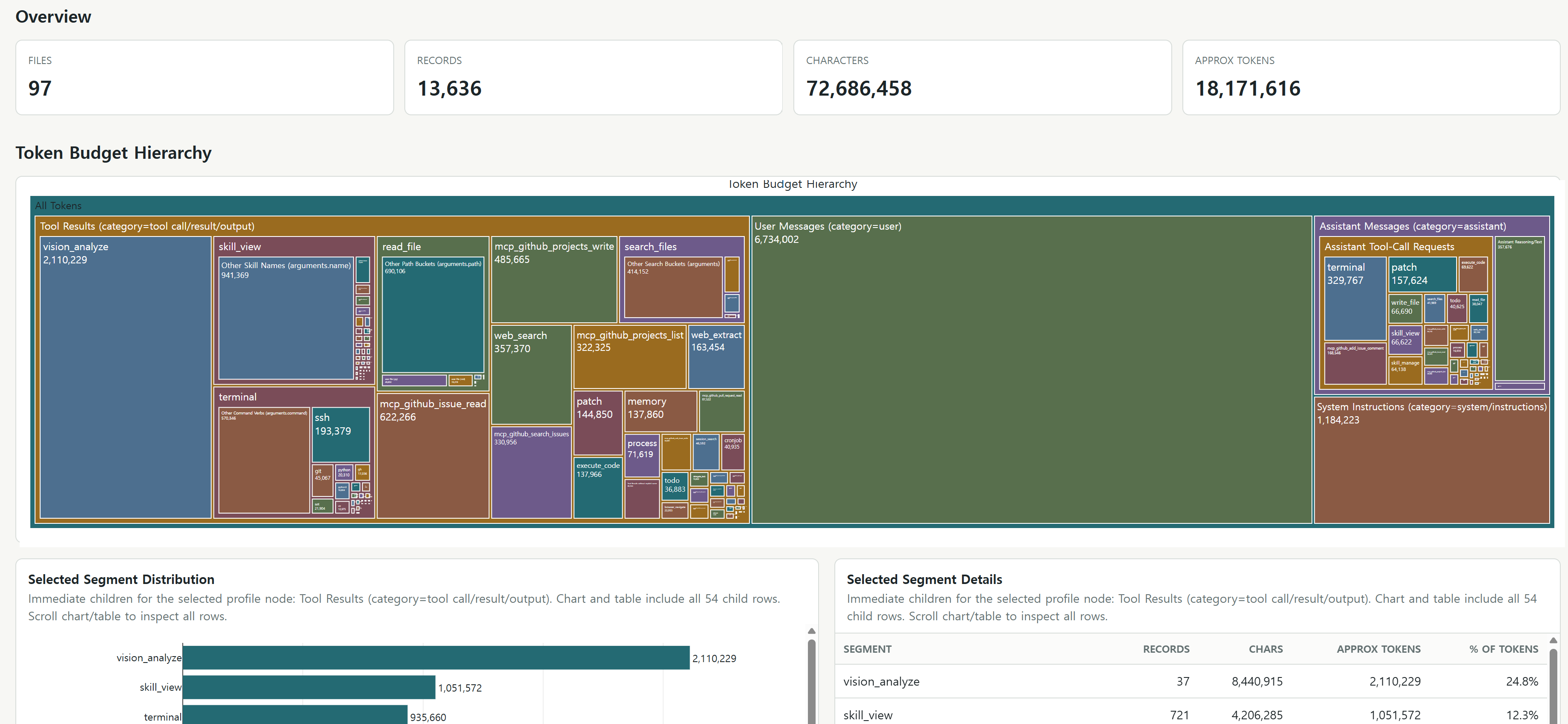
Last week I decided to create a simple web UI to visualize the token usage of agent trajectories. I used Hermes Agent’s trajectories as they are saved directly to JSONL files, making it easy to parse and visualize. It divides tokens in the trajectory into tool call results, user messages, assistant messages, and system instructions. For assistant messages and system instructions there was no clear way of subdividing them, so I just grouped them together. For tool results I could get more granular and group them by tool name.
I approximated trace payload tokens from number of characters. The tool with the highest token use was vision_analyze taking up almost 25% of total tool result tokens, which was surprising because I had only run it 37 times in the past 7 days, compared to terminal, which I ran 1579 times while only taking up 11%. I suspect this is because vision_analyze returns a lot of text. Another interesting finding was how much token volume came from GitHub MCP tools: the 4 highest tools (mcp_github_issue_read, mcp_github_projects_write, mcp_github_search_issues, mcp_github_projects_list) amounted to about 20% of total tool result tokens. It shows how a convenient interface for interacting with agents, like GitHub issues, can be quite costly in terms of token usage, especially if it is not optimized for token efficiency. It would be interesting to see if there are ways to reduce token usage for these tools, or if there are alternative tools that can achieve the same results with fewer tokens.