Motivation
Most web-browsing benchmarks focus on retrieving information that is rather easy to locate. BrowseComp is a collection of questions whose unambiguous answers exist on the public web but require persistent, creative, multi-hop browsing.
Data Collection
- Inverted Question: Trainers were encouraged to start with a fact, then created a question out of it by finding several characteristics from the answer that constrains the search space gradually.
- Difficulty Checks: Curators enforced difficulty via three checks: (1) unsolved by then-current models (GPT-4o with/without browsing, o1, an early Deep Research); (2) not accessible in first few pages of Google search results; (3) not solvable by a second human within 10 minutes.
- Caution on Data Leak: Authors discourage public reproduction of the examples to reduce leakage and include a canary string for corpus filtering.
What’s the title of the scientific paper published in the EMNLP conference between 2018-2023 where the first author did their undergrad at Dartmouth College and the fourth author did their undergrad at University of Pennsylvania? (Answer: Frequency Effects on Syntactic Rule Learning in Transformers) Sample question given to trainers
Results
- Human baseline: When trainers (not the question authors) were asked to solve the questions, they had a success rate of 29.2% (367/1255) with an accuracy of 86.4% (317/367).
- LLM grader: Models output Explanation, Exact Answer, and Confidence. The answers are graded via an automatic judge prompt adapted from Humanity’s Last Exam comparing the predicted answer to the reference.
- Low performing general models: GPT-4o (with and without browsing), GPT-4.5, and OpenAI o1 all perform poorly with accuracy below 10%.
- Deep Research: The Deep Research agent explicitly trained with data to be strong on tasks like these did much better, but still only got around half of the questions correct (51.5%).
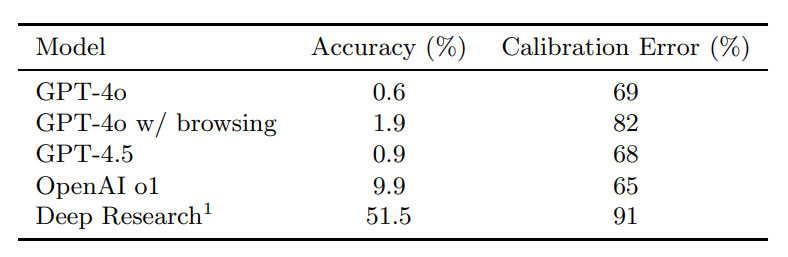
- Calibration analysis: Models that had browsing capabilities (GPT-4o with browsing, Deep Research) were found to struggle more with confidence calibration and often fail to convey uncertainty accurately.
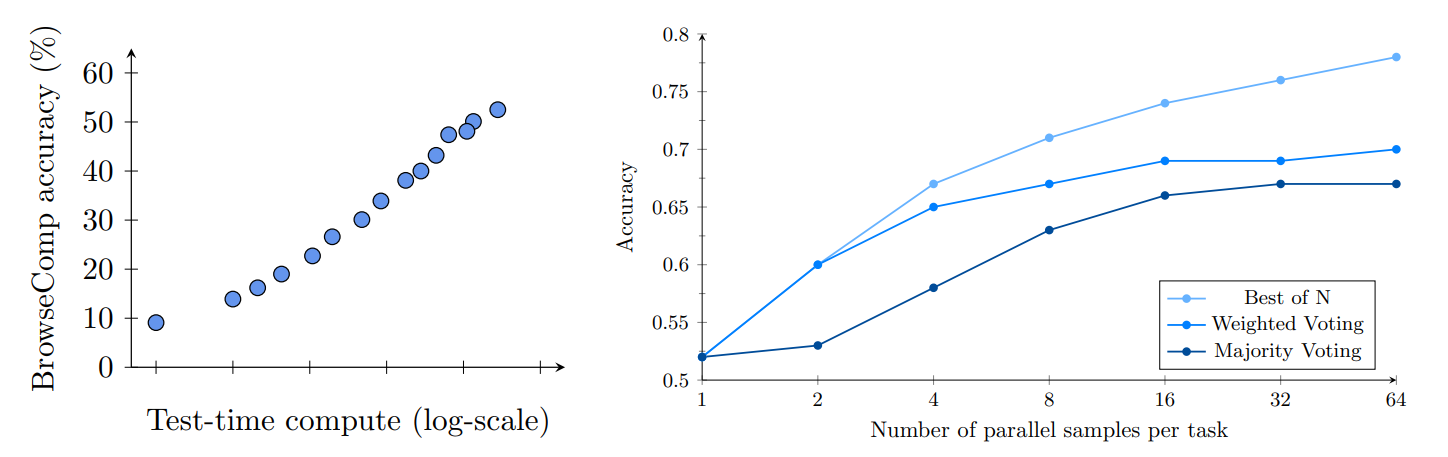
- Scaling test-time compute Accuracy scales smoothly with test-time browsing effort. Trying each problem multiple times and aggregating them also improves accuracy significantly.
Contributions
- Challenging web-browsing benchmark. Questions in BrowseComp demand agents to search with persistence and “creativity”.
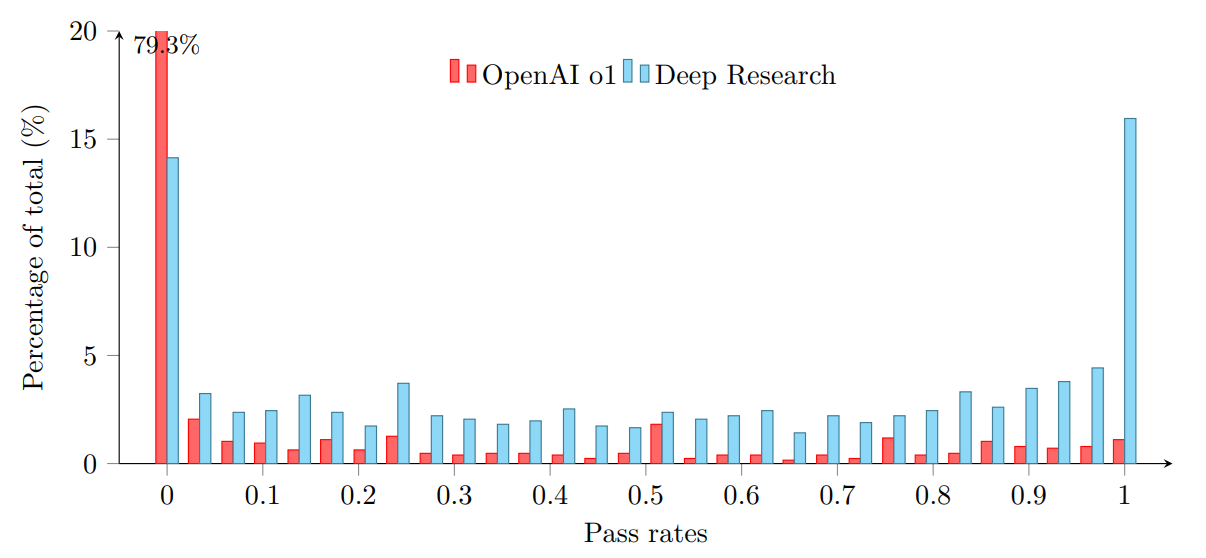
- Good distribution of pass rates: Based on the success rate of Deep Research agent on the benchmark, the questions have a well-balanced distribution of pass rates except for the fat tails (0% pass rate in 14%, 100% pass rate in 16%).
Remaining Questions
- As authors mention, these questions are useful incomplete proxies. How well do these questions simulate real scenarios? In real world, users may be unsure about certain facts, or they could provide incorrect or partially wrong facts.
- Considering Deep Research was trained specifically for this task, the 51.5% seems more like an upper bound than a number to compare other models with.
- Calibration error of 91% seems extremely high - what is the scale? Is 100% not the maximum error rate?
- How does giving more “browsing effort” work in practice?
- Authors attribute the performance improvement from multiple attempts to the fact that BrowseComp questions are easier to verify than to find the answer. However, since the runs are done in parallel, isn’t every attempt “finding” instead of “verifying”?
- Authors gave Deep Research the ground-truth answer and asked it to retrieve supporting evidence, upon which the agent succeeded in most cases. How was “success” measured here?
To Read More
To Follow Up
- BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent: Fixed ~100K corpus for fairer, reproducible comparisons. Good for disentangling retriever vs. agent