Motivation
Large dense LLMs scale quality with parameters but are expensive to serve. Sparse Mixture of Experts (SMoE) allows increasing the number of parameters while controlling cost and latency by routing to “experts” to reduce the number of “active” parameters. Mixtral 8x7B selects two experts out of 8 at each layer, allowing 47B parameters while only paying for 13B active parameters.
Method
- Backbone: Decoder-only transformer with the same block design as Mistral 7B.
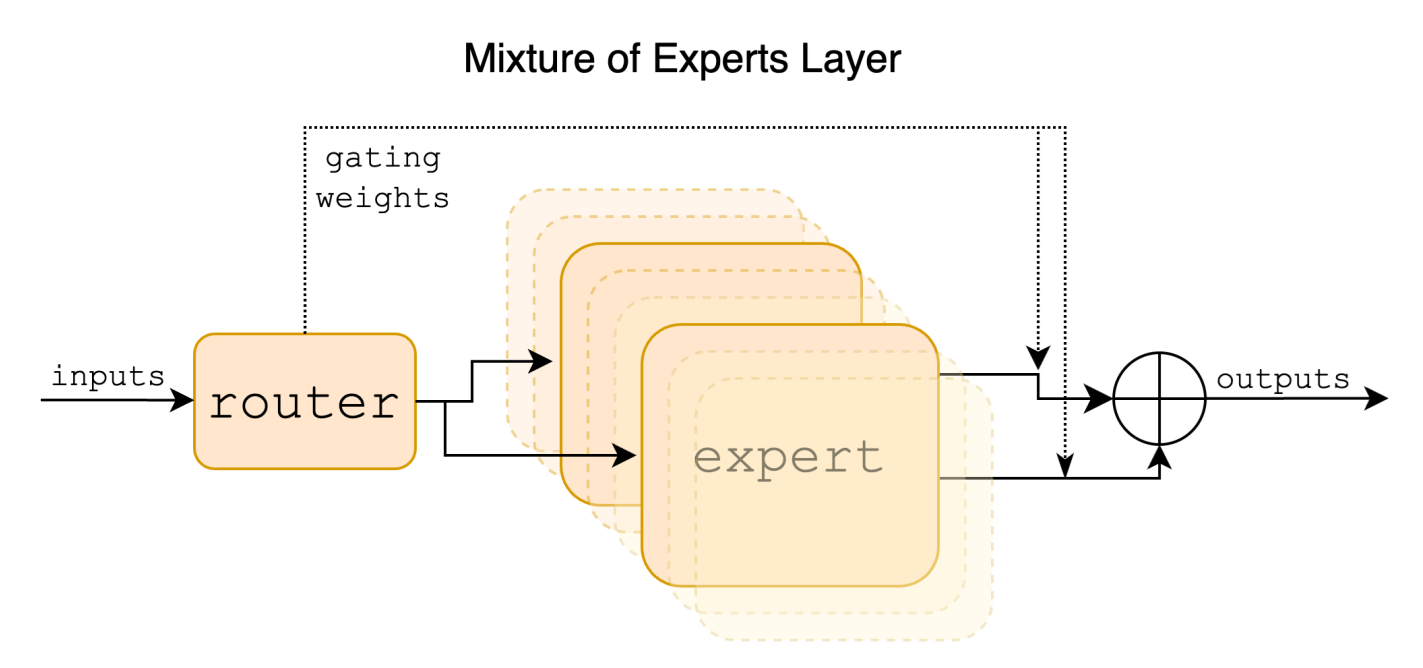
- Mixture of Experts: Feedforward network in each layer is replaced by 8 feedforward “expert” networks. A learned router selects 2 of the 8 experts and computes a weighted sum of their outputs (token-wise, layer-wise).
- Gating Network: The logits of the top-2 experts are passed through softmax to compute the weights.
Results
Mixtral matches or beats Llama-2-70B on many standard benchmarks using 1/5 of the “active” parameters (13B vs 70B) or 2/3 of the total parameters (47B vs. 70B). Instruction-tuned variant (Mixtral-Instruct) reaches performance comparable to GPT-3.5-Turbo.
The authors also analyze the distribution of selected experts across different domains (Math, Biology, Philosophy, etc.) Surprisingly, the assignment of experts did not follow a clear pattern based on the domain. Instead, they find some syntactic behavior and positional locality.

Contributions / Why It Matters
- Practical MoE at scale: Mixtral proved the capability of MoE by delivering performance of a 70B model with 13B active parameters.
Remaining Questions
- Limit in passive parameters: Mixtral uses 2 out of 8 experts, allowing for 13B active parameters out of 47B total. The total number of experts probably cannot grow indefinitely - where is the limit?
- Training Data: What data was Mixtral trained on? How much was multilingual data upsampled?
- Source of reduced bias: Where does the improvement (over Llama) in bias benchmarks come from? Does the MoE architecture play a part, or is it the training data causing it?
- Evidence of Syntactic Behavior: Is same expert being used for words like “self” in Python and “Question” in English enough to claim syntatic behavior?