Neural Fitted Q Iteration (Riedmiller, 2005)
Seungjae Ryan Lee
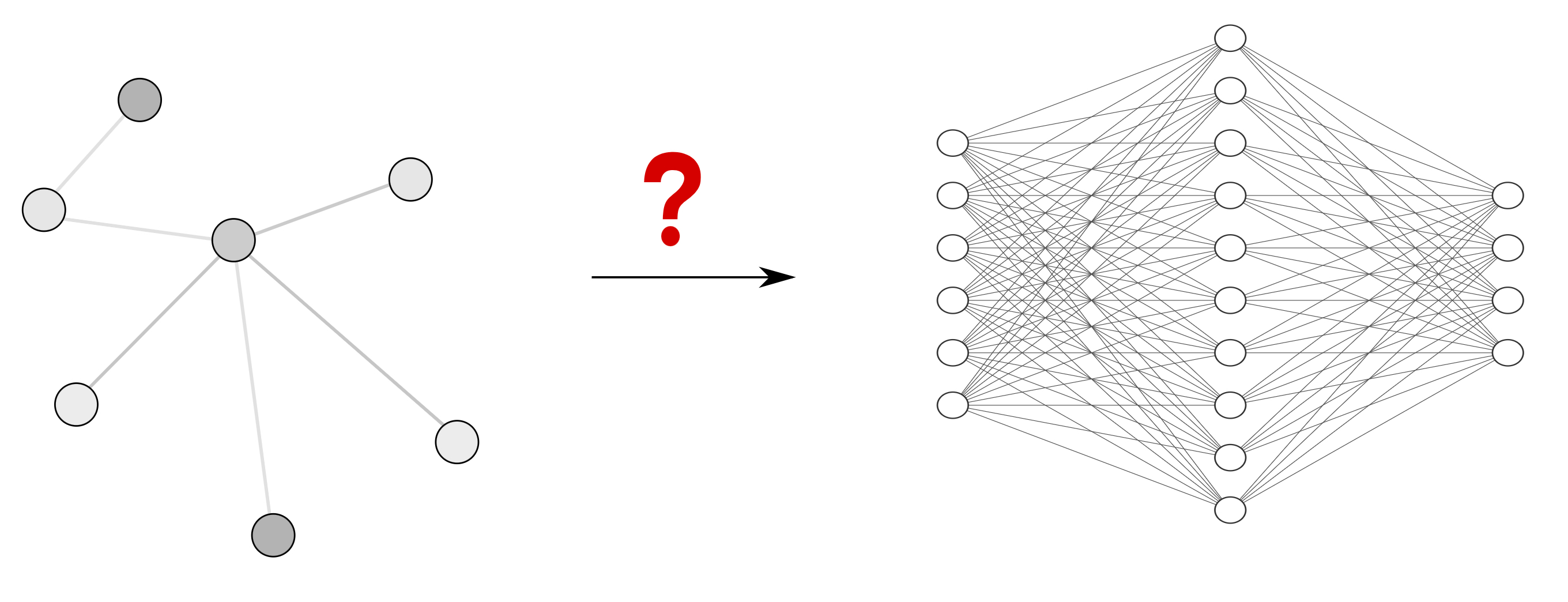
This paper introduces NFQ, an algorithm for efficient and effective training of a Q-value function represented by a multi-layer perceptron. Based on the principle of storing and reusing transition experiences, a model-free, neural network based RL algorithm is proposed. The method is evaluated on three benchmark problems. It is shown empirically, that reasonably few interactions with the plant are neeed to generate control policies of high quality.